1, 2, 3s of Applying Data Science to Business: A Walkthrough
I’ve been consulting businesses on how to apply data science to increase their revenues for a while, but I’ve decided that I wanted to open source my knowledge or at least layout my methods
Analyze your data
Select your model
Run your model, is it the correct one?
1. Look at your data before you run it
This is a surprising mistake a lot of new data scientists will make. Make sure to talk to the person with domain expertise
Check for
N/A (Missing) values. If something like 90% of the data is missing then drop the feature unless N/A is supposed to mean 0. Otherwise, impute N/A first with median/mean, then an algorithm
Correlations. If you’re running linear models, correlated features will break your algorithm.
Distributions. If the feature is skewed you can run a log over the values to normalize the distribution. You also want to see if you’re classifying for a rare event where for example 98% of your “y” data is “no cancer”.
Types. Continuous, binary, and if they’re categorical you’ll need to give them a one hot encoding
This is my favorite package for giving me a quick EDA of all 3. pandas-profiling
2. Pick a model to match the data (this is a 2 year masters program)
Now that you know what your data looks like, figure out what you want your algorithm to do. Don’t just jump in with a neural network because it’s fancy, you’ll quickly overfit if you have 100 data points and 40 layer network. Often times linear or logistic regression will do the job and are faster to train/easier to analyze.
Regression. You are trying to predict a number value like rent or revenue
Classification. You are trying to predict a category like “will this person be a lead or not”, or “what type of weather (rain/cloudy/sunny) will we have tomorrow”.
Clustering. Often useful for unsupervised learning. What group would this belong in, if I had the zip code of my clients I could bucket them into avatars based on their demographics to other similar clients.
Dimensionality Reduction. You have too many data points and want to consolidate them in order to run your model leaner and faster. Commonly used in conjunction with Neural Networks
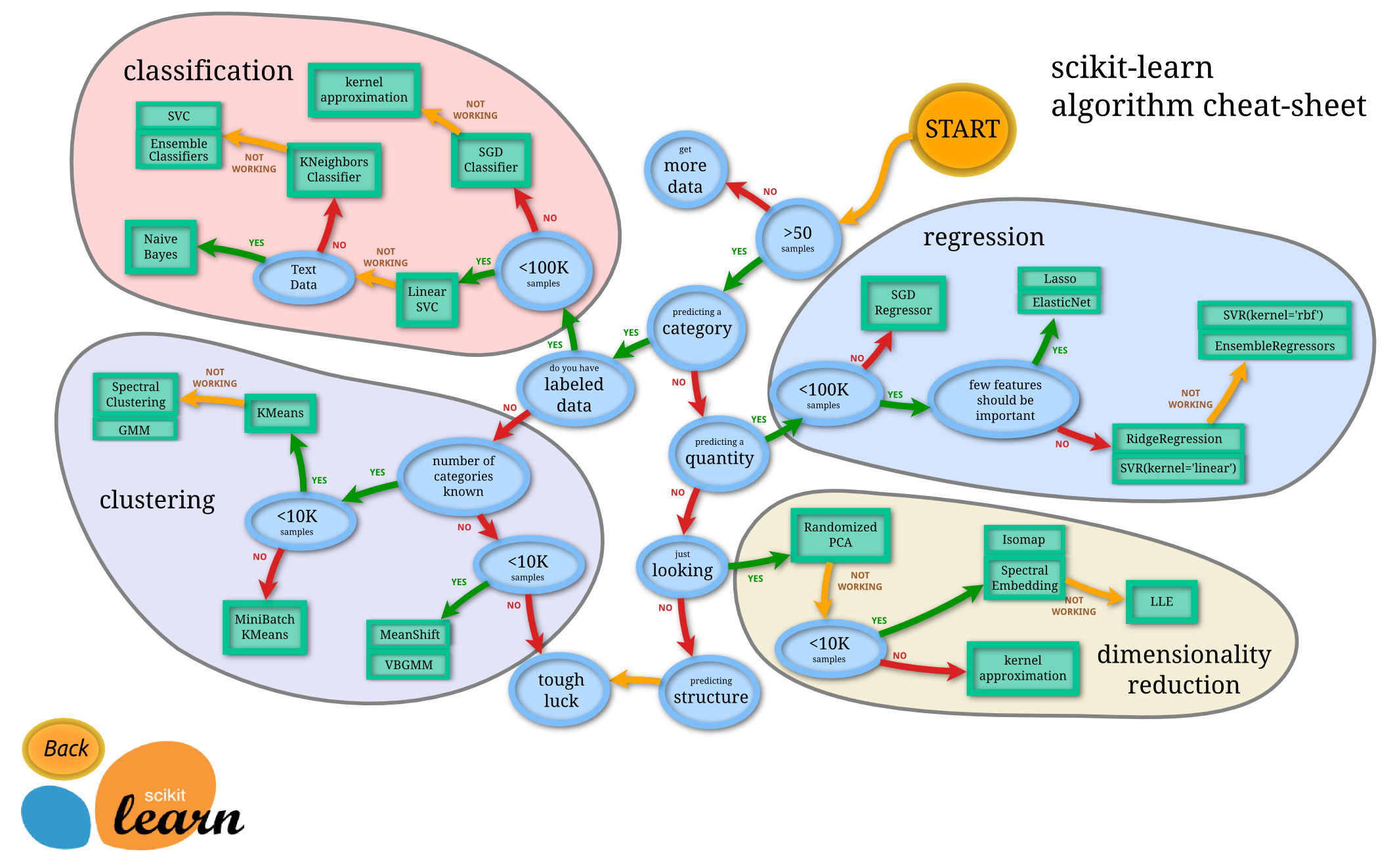
3. Is this model the correct one?
Split your training data and testing data. You have a training error and a test error, why is this important?
When your training error < test error, you have over-fitted. Your model is not generalizing well to new data.
Increase amount of data. Either find more or augment data
Regularization
Dumb down your model so it is less complex
Removing features
When your training error > test error, you have under-fitted. Your model needs more complexity to adjust to new data
Go from Linear regression/Logistic regression -> tree based models (GBML/Random Forest) & SVM -> Neural Networks
Reduce regularization parameters
Add new features
When your training error == test error & you think you have approached the theoretical limit of your task (computer vision is at 5% for example because that’s what human performance is), then you don’t need to do much more.
Bonus: Is my model accuracy correct?
This goes back to point 1 when you have a classification model where the outcome value is overrepresenting one result. For example, if you have a model that’s trying to detect cancer and only 2% of patients are ever detected to have cancer, then your model could end up guessing “no cancer” 100% of the time and still achieve a 98% accuracy.
This is where precision, recall, and F1 scores come in handy. Precision in the example above would be high at 98%, but recall would be at 2%. This would give a total F1 score of precision x recall = 1.96% (Best is 100%).
